
About Apache Tika
The project is hosted by the Apache Software Foundation. It supports detecting various file and content types. There is a full list of supported formats. When having a look at the list that displays the supported formats, many document formats are listed in there. E.g. text/plain, text/xml, the propritary Microsoft OOXML or the office standard Open Document. Furthermore images (image/gif, image/jpeg, image/bmp or image/tiff), videos (video/avi, video/mpgeg or video/mp4) and audios (audi/ogg, audio/x-wav or audio/mpeg) can be recognized by Tika. Even feeds (application/rss+xml, application/atom+xml) may be recognized. And many, many more …
There are various ways to detect files and content. There is a frontend, a server, a library for java. The results might be returned as plain text or json. Even html is possible.
Each file, each content or stream contains either some header information, or some unique characteristics that help to identify the content type. Tika is using this approach. There is a parser for each content type, that Tika is able to recognize.
Running the Apache Tika Frontend
Apache Tika provides a graphical user interface for determining content. The frontend prints all the information that Tika is able to extract. E.g. the Content-Length, Content-Type or Content-Encoding. The Frontent is really basic and simply prints all the information line per line. For a non technical user this might be quite hard. Otherwise a non technical user normally wouldn’t use such a tool.
In order to run the Tika frontend simply use the command line option -g or --gui.
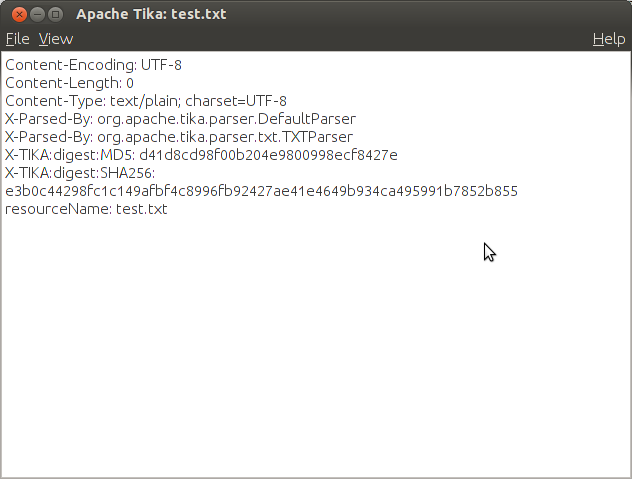
Apache Tika Frontend
Using Apache Tika within command line
Additional to the graphical user interface Tika is useable via command line. When running Tika with the command line option -d or --detect, Tika detects the content type of a file and then prints the result to the command line.
$java -jar tika-app-{version}.jar -d {file}
text/plain # document type of the file that was probed
$
Using Apache Tika with Java
When implementing a Java based software, Tika may be used directly as library. Using Tika is quite simple. There is a various number of ways to detect content with Tika the programmatic way. Simply see the following code snippet that describes the usage of Tika. It’s possible to detect anything that is given by a stream, but detection via file name is possible too. In this case the file extension is used to “detect” the content. Furthermore a file or the path to a file may be used for detection. But the binary data of content or a URL can be used too.
Tika tika = new Tika(); tika.detect(InputStream stream); // the document stream tika.detect(String name); // the file name of the document tika.detect(File file); // the file tika.detect(Path path); // the path of the file tika.detect(byte[] prefix); // first few bytes of the document tika.detect(URL url); // the URL of the resource
Dependencies for Development
For developing software that uses Tika the library can be added as dependency. How to use Tika with maven or gradle is described below. Of course other dependency management systems like Ivy, Grapes, … may be used.
Maven
<dependency> <groupId>org.apache.tika</groupId> <artifactId>tika-core</artifactId> <version>1.13</version> </dependency>
Gradle
dependencies {
compile 'org.apache.tika:tika-core:1.13'
}
Sources
Apache Tika
Transparently improve Java 7 mime-type recognition with Apache Tika
Determining File Types in Java
Get the Mime Type from a File